
How to Search the UTA Libraries Web Archives

The purpose of The Compass Rose is to raise awareness of Special Collections' resources and to foster the use of these resources. The blog series also reports significant new programs, initiatives, and acquisitions of Special Collections.
This blog post is the fourth in our new "How To" series focused on using online resources to find Special Collections material.
What is Web Archiving and How Do We Preserve a Website?
Web archiving is the process of collecting websites and the information that they contain from the World Wide Web. Web archiving is a similar process to traditional archiving of paper documents. The information is selected, stored, preserved and made available to the public. Websites are archived through web crawls, which capture digital snapshots of a website at the time of the crawl.
UTA Special Collections uses an automated web crawler operated by the Internet Archive to preserve websites. The Internet Archive is a 501(c)(3) non-profit founded in 1996 with the purpose of offering permanent access to collections that exist in digital format. In fall of 2005, the Internet Archive began pilot testing their new subscription service, Archive-It, which allows institutions to build, manage and search their own unique web archives.
Special Collections began using Archive-It in 2016 to archive websites directly related to our collecting areas. We have archived over 600 Gigabytes of data and over 150 web pages. The UTA Special Collections Web Archives allows you to view websites from past dates, providing free and open access to the information long after the sites have changed on the live web.
Why do we collect these websites?
The internet is a vital means of communication. The websites UTA Special Collections preserves document information that supplements our physical collections. It is becoming more common for information to be published solely on the web so some of the information preserved in web archives may never be documented in a physical format. Websites are an essential part of how entities like universities and labor organizations function and through the Archive-It service, we can preserve and promote access to websites with enduring value to our collections.
What websites does the UTA Special Collections preserve?
The UTA Special Collections Web Archives is separated into five collections:
These five collections correspond to physical materials already held by Special Collections.
Browsing the Web Archives
The first step to searching or browsing archived websites is navigating to the UTA Special Collections home page on Archive-It. Researchers can browse each collection by clicking on the collection name from the home page as shown in Figure 1.
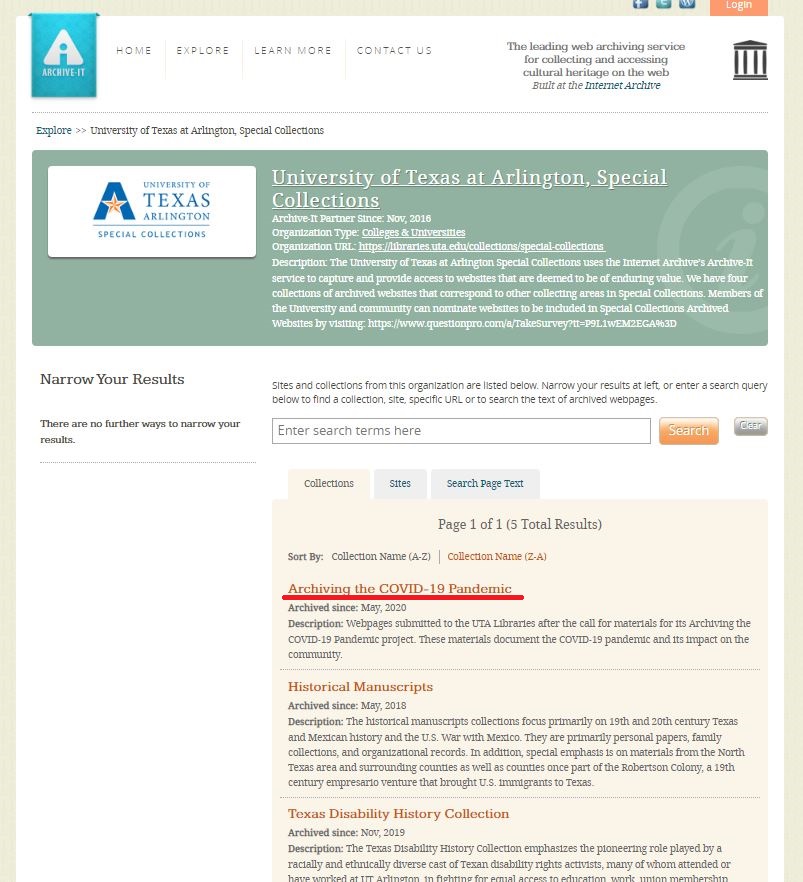
Figure 1. Screen capture of Archive-It home page for UTA Special Collections
Once you have navigated to the collection page you will be able to see a complete list of archived websites for each specific collection as shown in Figure 2.
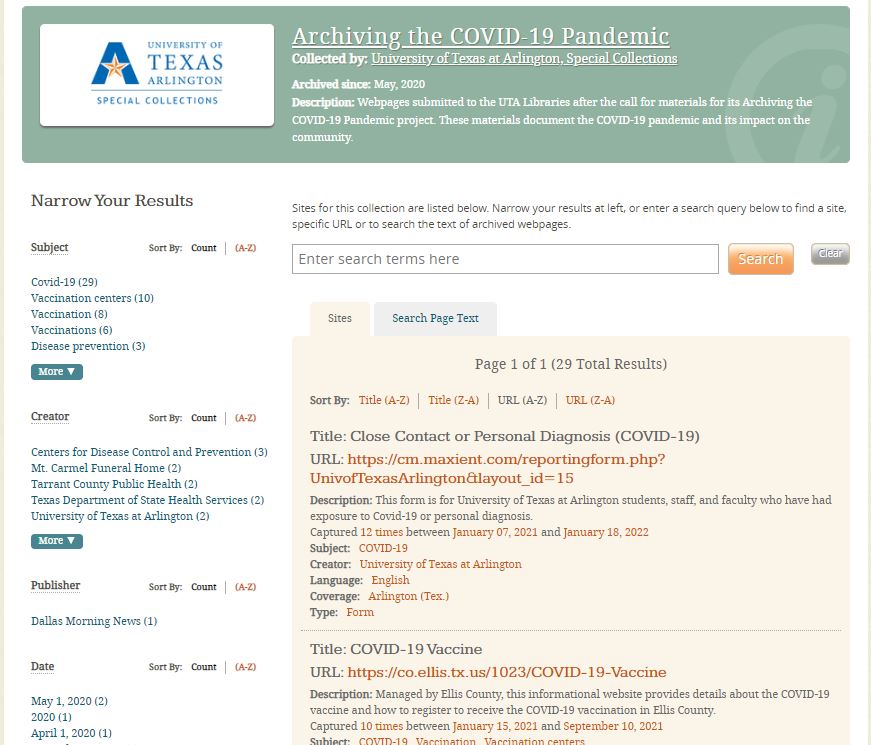
Figure 2. Screen capture of Archiving the COVID-19 Pandemic Collection page on Archive-It
From the collection page you can narrow your results based on the fields on the left-hand side as shown in Figure 3. Results can be narrowed by subject, creator, publisher, date, format type (website, form, video, etc.), language, and geographic coverage.
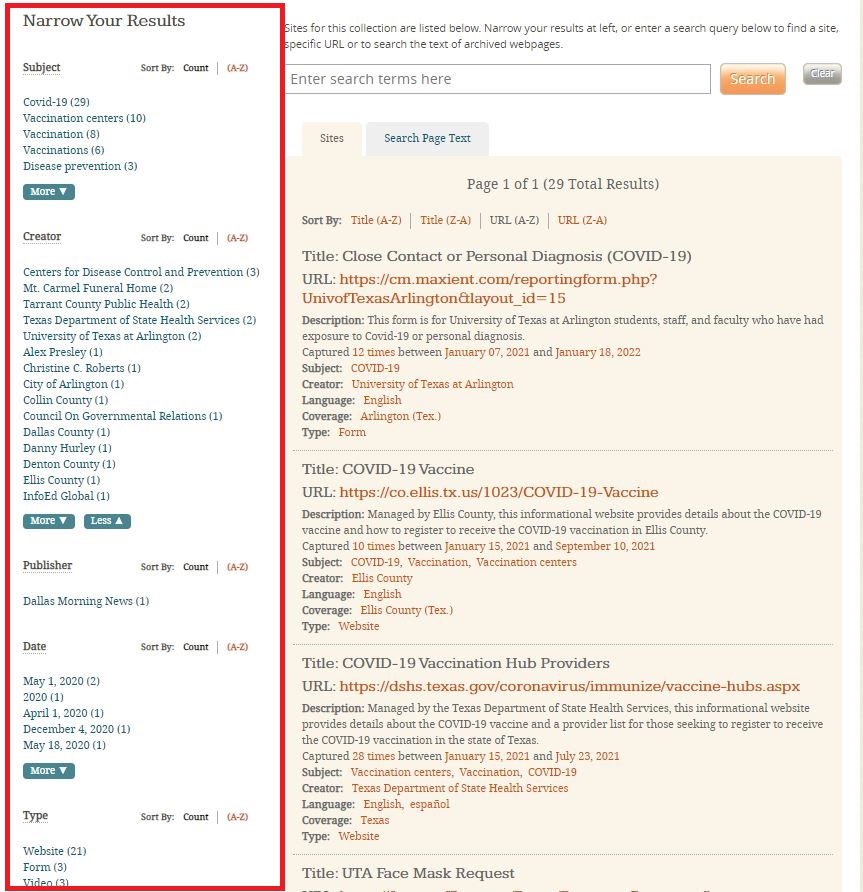
Figure 3. Screen capture of the Archiving the COVID-19 Pandemic Collection page on Archive-It with the search filters outlined in red.
For example, if you narrow your results by University of Texas at Arlington as the creator in the Archiving the COVID-19 Pandemic Collection it will display 2 results as shown in Figure 4.
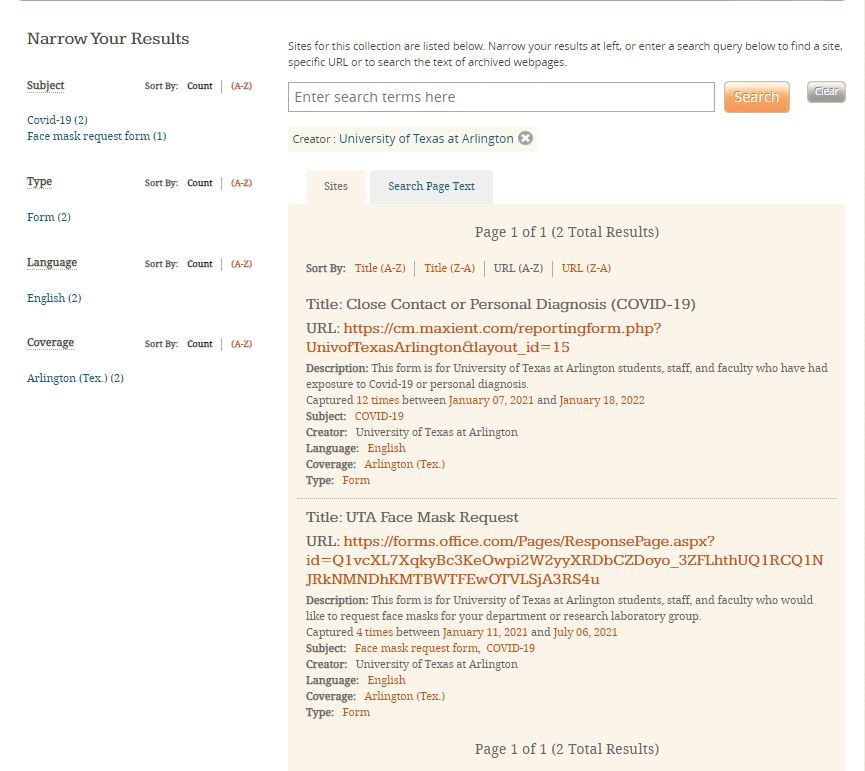
Figure 4. Screen capture of the results page for the University of Texas at Arlington creator in the Archiving the COVID-19 Pandemic Collection on Archive-It.
On the results page, you can view more information about each individual web page that was captured. As shown in Figure 5, information about individual web pages that were captured includes the title, URL, description, subjects, creator, language, geographic coverage, format type, and the dates and number of times the web page was captured. To view the archived web pages, click on the URL for a specific website.
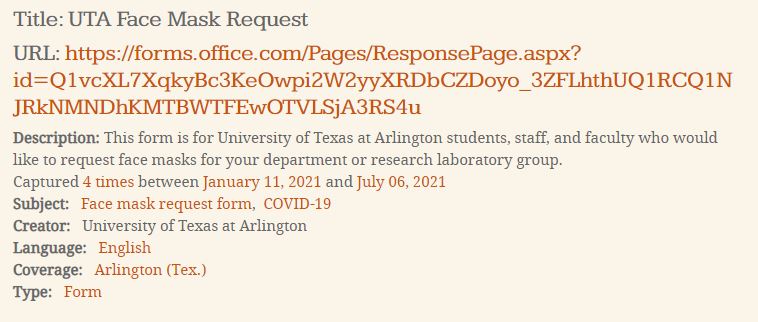
Figure 5. Screen capture of the result for the UTA Face Mask Request web page.
Archived websites are captured on a reoccurring basis to document the changes to a page over time. Depending on the frequency of these changes, websites may be archived on a quarterly, semiannual, or annual basis. In some cases, websites are only captured once to retain the information at that time. The page displayed in Figure 6 provides access to all of the capture dates for the specific web page. Dates the page was captured are highlighted in blue. To view the archived webpage on a specific date, select the highlighted date in the calendar.
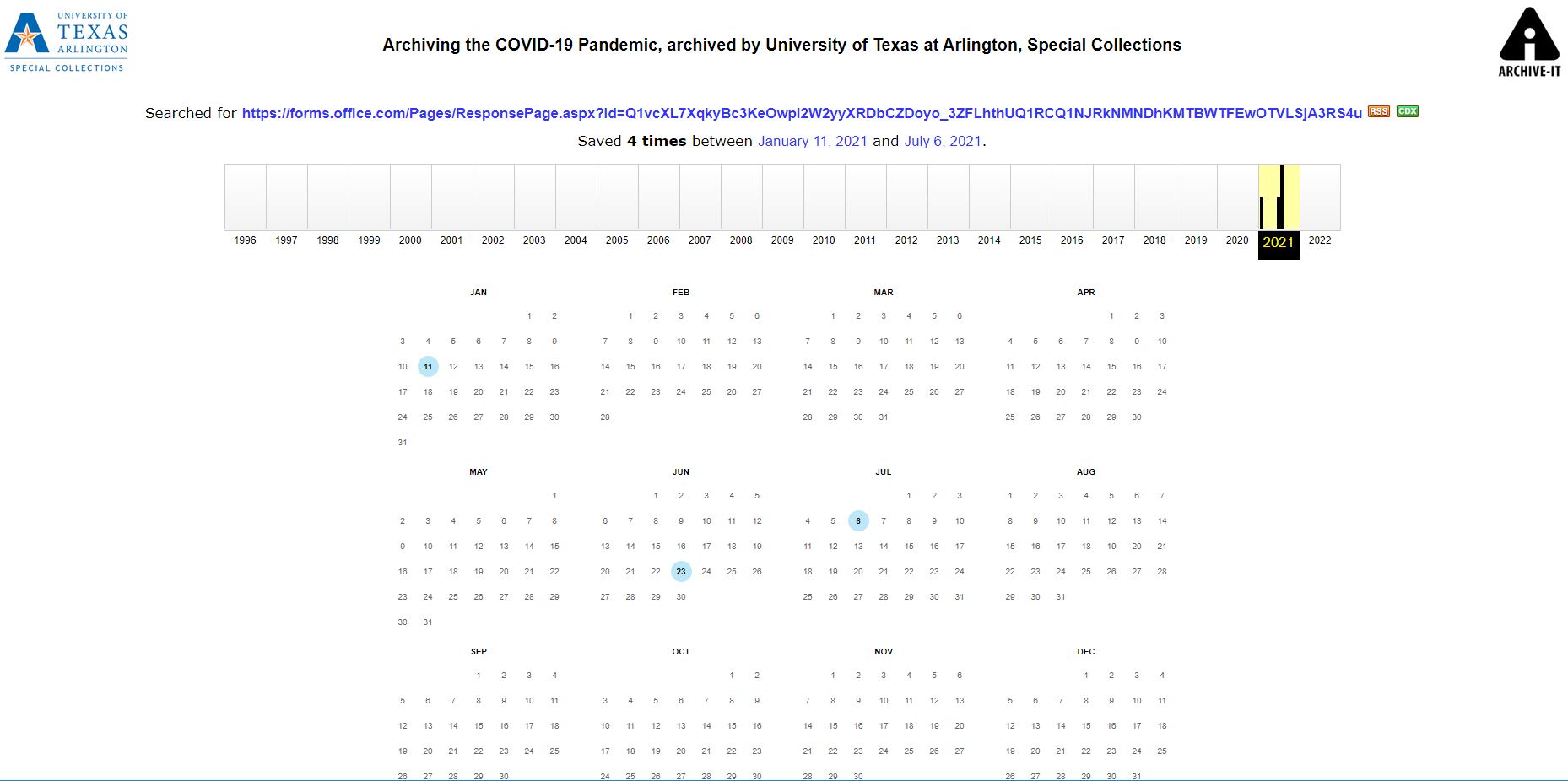
Figure 6. Screen capture of the Archive-It page displaying all captures for the Close Contact or Diagnosis (COVID-19) web page.
You can now view the archived web page on the specific date you selected.
Searching the Web Archives
To search the UTA Special Collections Web Archives you simply enter your search term into the search box on the Archive-It home page for Special Collections as shown in Figure 1.
Archive-It will search all the metadata entered as well as the text of the page. Any results for your search will be displayed and sorted by the closest match. The three tabs above the search results will allow you to browse matches for collections, metadata for individual websites, or the text of entire websites as shown in Figure 7.
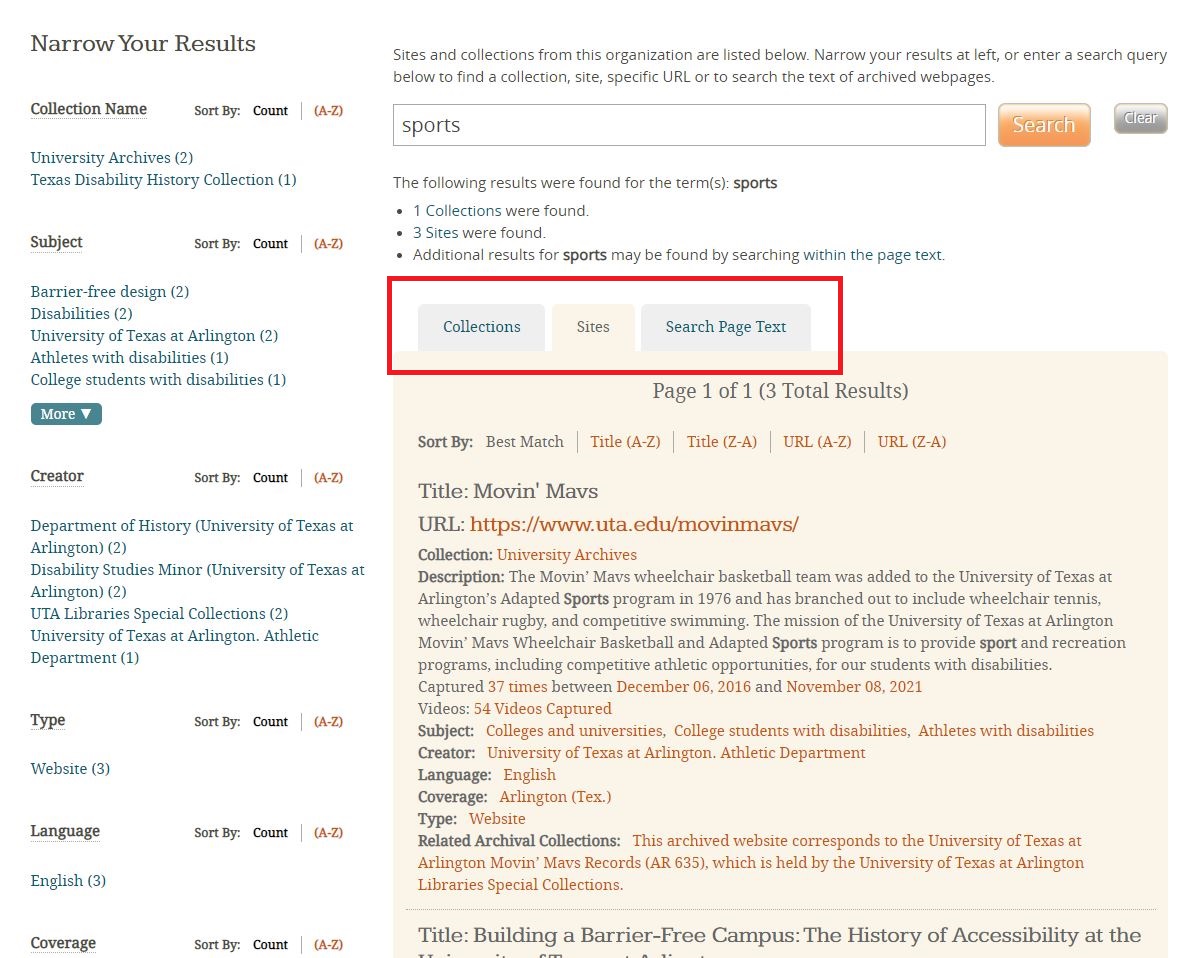
Figure 7. Screen capture of the Archive-It search results page for "sports” on the Sites tab
Advanced searching can be done to the left of the search results when searching within the text of a page as shown in Figure 8.
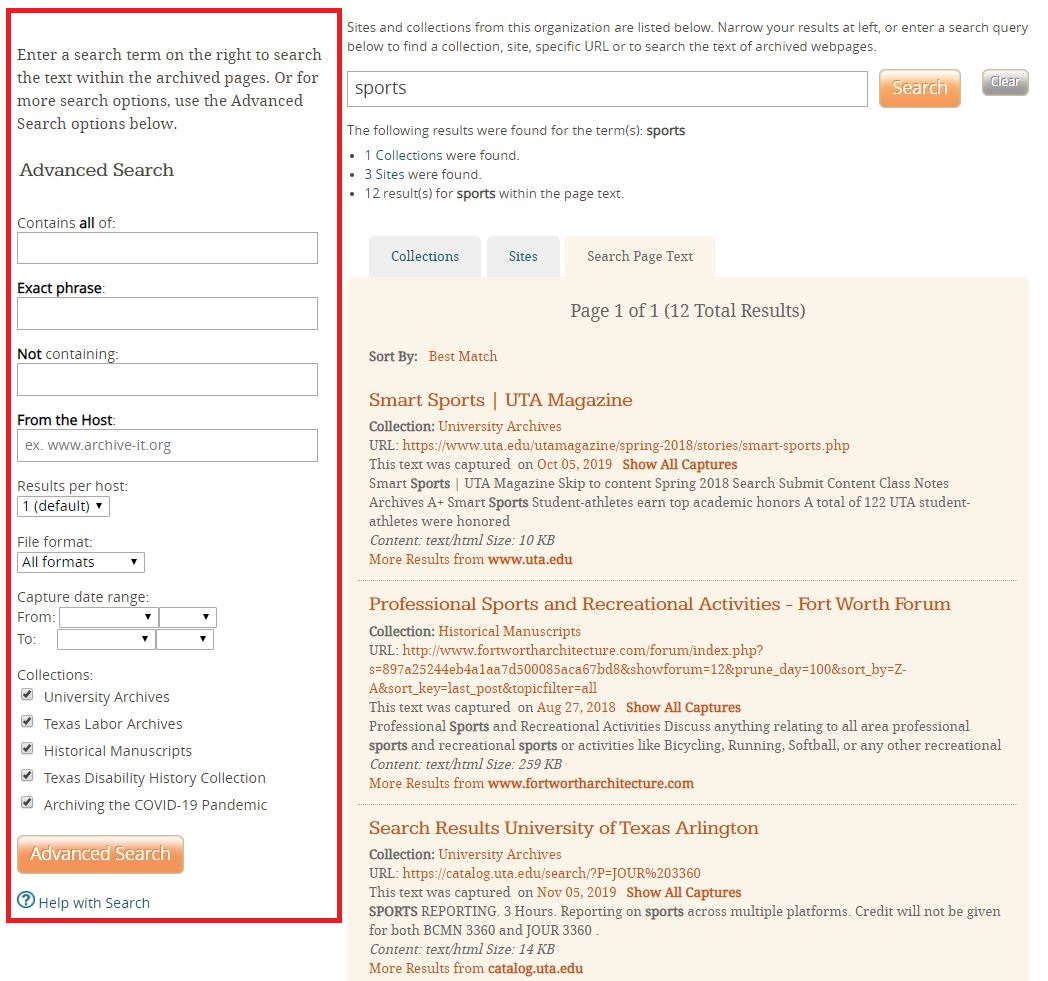
Figure 8. Screen capture of the Archive-It search results page for “sports” on the Search Page Text tab
Why is preserving websites important to the historical record?
Technology and website appearances have changed and will continue to change rapidly. In some cases websites can even lose data, both intentionally and accidentally. The impermanence of the web has created a necessity to archive the information. Websites are regularly updated and the information is constantly changing. It is essential to capture these records for preservation.
Add new comment